Being able to run server-side JavaScript predates Node.js by quite a bit. In early 2000's I was working on an application server called Tango and one of its features was the ability to run server-side JavaScript code in Mozilla's JavaScript engine, SpiderMonkey. Later on, I started using ASP with JavaScript, which worked just fine on its own for smaller tasks and for heavy workloads I interfaced ASP/JavaScript via COM with C++.
Eventually, Classic ASP got too slow and too outdated and the choice was either to move to ASP.Net or Node.js, which was picking up steam at the time. I ran a number of performance tests while trying to figure out a good path for transitioning a large application off Classic ASP and without concurrency Node ran JavaScript code incredibly fast, leaving equivalent ASP.Net tests far behind, but multiple concurrent requests made it evident that the more JavaScript is in a Node application, the slower it runs. This pretty much is still the case today.
How fast is Node, anyway?
Note that the purpose of this comparison was not to compare C++ vs. JavaScript, but rather to establish a baseline for further Node tests against code that is written in both languages.
For a simple speed test I wanted to run mostly linear code that allocates minimum amount of memory and puts some load on the CPU. After looking around for a good sample, I settled on running MD5 digest repeatedly against a small fixed-length string. I took blueimp's JavaScript MD5 implementation and modified it to leave only function calls, bit shifts and math. It no longer produced MD5, but rather a predictable value that can be used to verify that both tests applied the same logic to input. I also ported this modified code to C++, so both tests run similar code. The source for both tests is in the md5-like directory in the test source archive.
Node uses Google v8 to run JavaScript code. The v8 is very well designed and implemented and it does wonders with JavaScript. It basically compiles JavaScript into machine codes and as long as the code doesn't do something silly, JavaScript runs blazingly fast. The v8 architecture does not stop there, and has many other fascinating designs that contribute to the overall performance, like arrays using C-style arrays underneath and not hash maps, when possible, and many other wonders.
Good design and implementation translate into quite amazing v8 performance numbers. These are the times of running each MD5-like test in a loop 20 million times.
JavaScript: 12.432 sec C++ : 7.397 sec
JavaScript code in this test runs only about 40% slower than fully optimized C++ code, which is remarkable, especially, given that it still calls some functions, manages some variables and compiles the code as it runs it.
However, real applications in JavaScript do more than just bit shifts and math, so running full MD5 implementation in both cases against the same ASCII string mixed in with the digest in each iteration produced more realistic numbers.
JavaScript: 63.765 sec C++ : 7.810 sec
Note that unlike the md5-like test, the C++ test above uses the reference MD5 implementation from RFC-1321 and not the JavaScript code converted to C++. It should also be noted that in a real C++ application the resulting digest will be passed around in STL strings, which will slow it down a bit as well, as can be seen in further synchronous tests for the same number of iterations. The source for both tests is in the md5-test directory in the test source archive.
The event loop
There are two critically important components at the heart of Node - libuv, an asynchronous I/O and threading library, and v8, the Google's JavaScript engine.
The libuv event loop provides a very efficient way to monitor multiple event sources, such as network sockets, file handles, timers, etc, and make calls to registered application functions associated with every event type. libuv allows only one event loop per thread, which is what Node runs on its main thread.
The v8 engine runs JavaScript in self-contained runtime environments called v8 Isolates. Each v8 Isolate maintains completely independent JavaScript runtime state, which includes all variables, functions, pending callbacks, does garbage collection and a bunch of other things. Each v8 Isolate always runs on a single thread at a time. The v8 uses its own event loop for various purposes, such as calling asynchronous callback functions.
Node wires these two components together and routes libuv events to corresponding JavaScript callback functions within the primary v8 Isolate maintained by Node, always in the context of the main Node thread. This means that as long as v8 is running JavaScript code, asynchronous events handled by separate libuv threads and asynchronous JavaScript callbacks are queued within libuv and v8 and will be sitting in their queues until JavaScript returns from the current call stack.
Cooperative multitasking
So, how is it that Node running JavaScript on a single thread can handle multiple HTTP requests? This is where the good old cooperative multitasking comes in. Whenever JavaScript requests I/O, sets up a timer, calls a native module that supports asynchronous work, and so on, it gives control back to Node, which runs JavaScript for some other HTTP request.
Consider this timing diagram in which JavaScript code requests some asynchronous work, like reading data from the database, and then processes the results in an asynchronous completion callback. The green arrow shows the time when another Node request may be handled.

As long as each HTTP request handler in JavaScript runs quickly and handles every lengthy operation asynchronously, Node can handle multiple requests in a way that appears to an external observer as if they are executed concurrently.
However, if any of those requests misbehaves and runs longer on the Node thread, it will disrupt all other requests and they all will take longer to complete, as shown on the diagram below, where the orange request delays the original request from picking up asynchronous work results and increases its request processing time.

The extent to which one request affects the performance of other requests depends on the mix of synchronous and asynchronous calls for all requests and the implementation language. Let's see how each of these bits affects the overall application performance.
Synchronous vs. asynchronous vs. implementation language
Each test described in this section is the same MD5 digest code running in a loop of 200 thousands iterations instead of 20 million iterations, which simulates more realistic web requests in terms of request processing times. The source for all tests is in the md5-node directory in the test source archive.
Timeline charts were captured with a debugging proxy called Charles. Concurrent 15-second tests were executed with JMeter.
Synchronous JavaScript MD5 Calls
Let's start with the most straightforward case - processing the entire request in JavaScript, which describes many actual Node applications parsing JSON payloads, formatting JSON responses, mapping out database schemas, grouping database results, and do other things that are so easy to implement in JavaScript.
This is a timeline chart of a series of synchronous requests made by 4 concurrent users in Charles. All requests started at the same time. Request #1 ran without waiting in the queue and it took 753 ms to complete. This is consistent with 20M iterations taking about 64 seconds in our baseline tests. Request #3 was next in the queue and it completed in 1.4 seconds, which includes 753 ms spent in the queue and about 647 ms of run time. Request #4 was next in the queue and completed in 2 seconds and request #2 completed in 2.7 seconds, both following the same pattern.
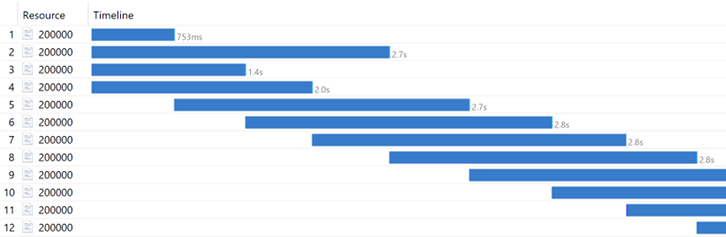
Charles sent request #5 as soon as it received the response for request #1 and request #5 was queued until the last request from the previous was completed (i.e. request #2) and then was processed in 700 ms. This pattern continues and all subsequent requests are staggered by one request time slot.
Because of the synchronous nature of these requests, processing time of each request will be the processing time of a single request without concurrency multiplied by the number of users. The table below shows the results of running this test in JMeter for 1, 2 and 4 concurrent users for 15 seconds.
| # of users | # of requests | Avg time (ms) | Max time (ms) | Throughput (req/sec) |
|---|---|---|---|---|
| 1 | 25 | 610 | 633 | 1.6 |
| 2 | 25 | 1244 | 1456 | 1.6 |
| 4 | 28 | 2348 | 2652 | 1.6 |
Notice that the number of requests that fit in a 15 second window and the throughput are the same for all test cases. This is because request processing time increased by the same factor as the number of users, so more requests were processed concurrently, but each of them took longer to complete.
Synchronous C++ MD5 Calls
Sometimes there is a C++ library available that produces the same result as some Node package. Let's see how using such library in a Node native module affects a Node application.
In this test each individual MD5 digest is computed in C++, still synchronously, but the loop is running in JavaScript, so every set of parameters and return values must be passed back and forth between JavaScript and C++
The timeline chart shows that this approach does not change the behavioral pattern - it just runs MD5 computations faster, so the request timeline looks similar to the previous test, except that each iteration takes about 4 times less to complete.

JMeter concurrency test also shows the same request processing pattern, except that it fits 4 times more requests in a 15 second window.
| # of Users | # of Requests | Avg Time (ms) | Max Time (ms) | Throughput (req/sec) |
| 1 | 101 | 148 | 171 | 6.7 |
| 2 | 100 | 301 | 444 | 6.6 |
| 4 | 104 | 589 | 919 | 6.7 |
Asynchronous C++ MD Calls
Asynchronous processing has been around for decades. It basically provides a way to queue a number of I/O operations and then process results as they become available, often in different order, compared to the order of queued requests.
Asynchronous processing is more efficient than naive threaded implementations, where a new thread is launched for every event, such as a new thread handling every incoming connection. Using too many threads requires more memory and creates resource contention that may slow down request processing to a point where it may actually run slower than if it was executed synchronously.
Using threading intelligently with asynchronous operations provides a tremendous performance benefit and will most of the time outperform single-threaded operations. The keyword here, however, is intelligently, which sometimes is hard to achieve if the nature of the underlying work is not deterministic.
This next test runs the same MD5 test loop in JavaScript and calls a C++ function computing a single MD5 digest value asynchronously. This means that for every MD5 computation JavaScript code must return control to libuv, which then goes through all of its event loop processing stages, and only then calls the MD5 completion callback, which queues another MD5 computation and the process repeats. Here is the timeline for this test:

Notice a change in pattern - now all 4 requests run concurrently and take the same time to complete. This is because the native asynchronous function yields control so often that each of the four requests is being scheduled to execute after each MD5 computation, which makes it look like they are all running in parallel. However, the response time of 1.5 second per request clearly shows that this pattern is as far from parallel execution as they come.
Interestingly enough, JMeter tests showed that 1.5 seconds is not even as bad as it gets, as the average request processing time was about 3 seconds for 1 and 2 user tests.
| # of Users | # of Requests | Avg Time (ms) | Max Time (ms) | Throughput (req/sec) |
| 1 | 6 | 2994 | 3015 | 0.3 |
| 2 | 12 | 2970 | 3001 | 0.7 |
| 4 | 48 | 1272 | 1452 | 3.1 |
This result could only be explained by some Node component using wait timeouts for some operations instead of using event triggers. It looked somewhat puzzling to me, so I ran 1-user and 4-user tests in VTune and libuv indeed spent 5 seconds of the 15-second 1-user test run waiting for I/O in GetQueuedCompletionStatusEx. The 4-user test spent most of its CPU time in setting up asynchronous operations and cleaning up after them and not in computing MD5 digests, as one would expect.
Apparently, 1 and 2 users didn't generate enough I/O for GetQueuedCompletionStatusEx to return quickly, but 4 users did, so the response time dropped to 1.3 seconds, which is similar to what I observed in Charles for 4 users. Further increasing the number of users made it worse again - 5 users received their responses in 1.7 seconds. I couldn't test more users on a 4-core machine, so I left it alone.
Asynchronous operations perform well when one knows that the amount of asynchronous work exceeds the asynchronous work setup cost. For smaller jobs, such as computing a single MD5 digest, it does not work quite as well because queuing asynchronous operations is more expensive than the operations themselves, as was quite evident in this test.
Knowing the nature of the asynchronous work is always a great help in these cases. In this example, combining multiple MD5 digests in one asynchronous work would make a huge difference, as further tests will show. In real-life applications, combining requested items in asynchronous requests will always work better than handling one result at a time, such as asking for a group of photos in a large album, a group of seats in a large venue, a group of records in some aggregation work, etc, instead of handling each of those items one by one.
Synchronous C++ MD5 Loop
The next logical step in these tests is to move the 200K-iteration loop into the land of C++. The next test runs this loop synchronously.
The result predictably follows the same synchronous pattern and handles a single request in about 115 milliseconds, which is about the same speed as we saw in the initial baseline test, since the bulk of the test is running C++ code.

JMeter concurrency test also shows the same pattern as the number of concurrent users increases.
| # of Users | # of Requests | Avg Time (ms) | Max Time (ms) | Throughput (req/sec) |
| 1 | 191 | 78 | 85 | 12.7 |
| 2 | 188 | 159 | 173 | 12.5 |
| 4 | 193 | 313 | 479 | 12.6 |
As fast as this test runs, it still holds other requests until it completes, so it is not a very good pattern in real-life applications. If one went through the trouble of creating a native module to handle some work faster, it makes sense to take one step further and do this work asynchronously. It is like calling
Asynchronous C++ MD5 Loop
Finally, the next test executes the entire 200K-iteration loop asynchronously on a libuv thread and calls a completion JavaScript function when it is done. This is how expensive computational work should be done in Node.

The pattern is very similar to the other asynchronous pattern, except that each request takes mere 130 ms. One interesting detail in this chart is that the right edge of these requests is staggered and not as evenly cut as on the asynchronous test above. This is because the entire MD5 loop runs asynchronously and needs the previous active request finish its asynchronous work before it can go back onto the main libuv thread, so the right edge of each request reflects this extra waiting time.
The JMeter concurrency test shows consistent performance improvements for all levels of concurrency because there are no excessive work queuing activities in this type of asynchronous work and there are enough CPU cores to compute all MD5 digests in parallel.
| # of Users | # of Requests | Avg Time (ms) | Max Time (ms) | Throughput (req/sec) |
| 1 | 186 | 80 | 87 | 12.4 |
| 2 | 365 | 82 | 102 | 24.3 |
| 4 | 655 | 91 | 128 | 43.5 |
This is the fastest way to process requests in Node, but, unfortunately, not the cheapest way to develop code, simply because developing in C++ and other threaded languages is always going to be more expensive, compared to JavaScript development.
Putting it all together
Knowing that an F1 race car can outperform an everyday vehicle on a race track does not mean that we all need one to go buy groceries. Every job requires a suitable tool and someone working on an app that handles less than a hundred thousand requests per day may not need a C++ backend to respond quickly. It really all comes down to how much of a maximum response time one is willing to accept and how many resources they are willing to throw at it to get there.
Acceptable Response Time
Let's define request processing time as the time it takes Node to run the code identified in the request. This time does not include time spent in any queue before the first line of JavaScript code is executed by v8, but does include all wait times for asynchronous completion calls.
Let's define response time as a as the time a request spends in all queues on the way to the v8, plus the request processing time.
Finally, let's define the maximum acceptable response time as the the amount of time between some user action in the UI that translated into an application request and the time the user got a usable result of their action in the UI, which does not make them want to open a support incident or start posting on message boards that this app is the worst.
Note that the maximum acceptable response time does not translate directly to throughput. Consider 250 ms as the maximum acceptable response time and consider 4 requests that came in one after another, without any overlap, on a single CPU system. Each request requires 100% of CPU to complete. The throughput will be 4 requests per second and each user receives a response in 250 ms. Now consider the same 4 requests received at the same time and processed without queuing. Each request will be processed by its own thread for 1 second because it will be constantly preempted by other threads and while the throughput will still be 4 requests per second, neither of those 4 users will be happy.
In a simpler case of a fully synchronous Node application, if a single request runs for 100 ms and the maximum acceptable response time is 300 ms, you can execute maximum 3 requests without exceeding the maximum acceptable response time. This means that if you expect 6 simultaneous requests, you will need a separate Node instance to handle those additional 3 requests to stay within 300 ms.
Asynchronous requests are not as easy to analyze because one needs to figure out not only how libuv threads synchronize back with Node, but also whether asynchronous work has enough CPU cores to run on and how other resources are shared. For the purposes of this section I will consider that the host computer has enough CPU cores for all asynchronous work and that this work is not dependent on any other resources, so the actual execution time of each asynchronous call is known and we can figure out all wait times with simple math.
Waiting Game
So far each of the earlier tests was focused on a specific way of executing its MD5 test loop. Let's dive in into the mechanics of executing more realistic concurrent requests. For example, a real life application could run a bcrypt password computation as one asynchronous call, process results of this call in JavaScript, save the resulting hash in a database with an asynchronous call and, finally, generate a response in JavaScript.
Let's see what exactly concurrent Node requests are waiting for. Consider the following diagram showing two concurrent requests doing some asynchronous work. The green request and the orange request have to wait a bit in the queue even before any of their JavaScript code runs, which is shown as the two left-most wait arrows. Once they start running, each sets up some asynchronous work and yields control back to Node. Later on, the green asynchronous work call needs to wait for the orange request to finish setting up their asynchronous work and the orange request needs to wait for the green request to finish processing the results of its asynchronous work, which is shown as the two right-most wait arrows.

The request processing time of each request includes its own time running on the Node thread, the time each spent waiting for its own asynchronous work and the time spent waiting for its turn to run on the Node thread after completing asynchronous work.
The diagram above suggests that for simpler cases when all concurrent workloads contain the same sequence of calls, we should be able to estimate the response time as a sum of all of these times. If the number of simultaneous users making asynchronous calls is N, the request processing time is T, the execution time of a synchronous call is S and the number of asynchronous calls is W, then it would look like this: T + (N-1) * S * W. The N-1 part assumes that each asynchronous call of one user is waiting until all synchronous calls of remaining N-1 users finish before it can synchronize back with the Node thread.
Note that this formula is not intended as a practical way to compute response times, but rather as a way to confirm actual response times for tests in the next section. It does not mean that it wouldn't work of an actual series of requests, but quite often it would be hard to get consistent call times from various components, such as databases, running under load and with various locking patterns.
This section should also make it evident that one bad request will disrupt the entire application. For example, getting quickly a couple of thousand seats for sale from a database and spending half a second in a JavaScript loop formatting a JSON response for each will slow down all other concurrent requests by half a second and if all of them are doing the same operation, then response time for each will be in seconds.
Requests with mixed call type
For this test I wanted to have at least 2 asynchronous calls followed by two synchronous calls processing results of asynchronous work. For this, I split the original asynchronous and synchronous tests loops of 200K iterations onto two loops, each running 50K iterations, so each request runs an asynchronous loop of 50K iterations, followed by a synchronous loop of 50K iterations and then repeats the sequence once again, totaling the same 200K iterations in one request as in previous tests, but now allowing all threads to run concurrently, similar to a real life application.
Note that synchronous calls run C++ code, which makes them more predictable in terms of timing, but for all intents and purposes it would be very similar to running JavaScript code, except that it would run slower and, depending on its variable use, may trigger more frequent garbage collection cycles.
The diagram below shows theoretical interaction between requests from 3 simultaneous clients. Requests from the same client have the same color. Hollow boxes show calls running on the corresponding thread and dashed boxes show waiting for asynchronous calls to synchronize back with the Node thread. Boxes with asterisks indicate when a sequence of calls from one client finished and the next one starts. The three small vertical bars on the Node thread indicate requests being received and almost instantaneously set up their initial asynchronous work. The significance of those bars is that for a new client request the first JavaScript call must wait for its turn to run on the Node thread.

The diagram shows a sequence of two requests for each user. The first set of requests is only shown to set up the scene in terms of waiting cycles for the second set of requests. The request processing time for each client in the second set of calls is 4 + 3 boxes. Note that in these counts I ignored the little green box in the middle that set up asynchronous work for the green client just to indicate that it waits a bit more while other clients set up their asynchronous calls in those vertical bars.
The size of a hollow box on a Node thread is 20 ms, which is a duration of a synchronous loop doing 50K MD5 iterations, and the size of a hollow box on a libuv thread is 21 ms, which is a duration of an asynchronous loop doing 50K MD5 iterations. This means that a single request without concurrency is expected to take 20+21+20+21=82 ms. Perhaps, it would be more descriptive to make synchronous and asynchronous calls of different duration, but it makes the diagram more complex, so I opted for the same number of iterations.
Let's put this theoretical diagram to the test and run it in Charles. Here's the timeline for 3 users from the first set of calls.

Ignore the actual times in the timeline chart above - it is intended to show the response pattern for each user, starting from the first set of requests, rather than actual response times. Node needs to process a few requests before all of Node machinery is primed and response times in Charles tests eventually align with times shown below in the 15-second JMeter test for 1 to 4 concurrent users.
| # of users | # of requests | Avg time (ms) | Min time (ms) | Max time (ms) | Std.Dev. | Throughput (req/sec) |
|---|---|---|---|---|---|---|
| 1 | 179 | 83 | 81 | 92 | 1.80 | 11.91 |
| 2 | 280 | 107 | 82 | 185 | 13.78 | 18.54 |
| 3 | 295 | 153 | 98 | 239 | 22.31 | 19.44 |
| 4 | 292 | 206 | 125 | 319 | 36.15 | 19.28 |
Let's see if the formula above (T + (N-1) * S * W) aligns with the actual results. Synchronous call time S is 20 ms, number of asynchronous calls W is 2, asynchronous call time is 21 ms, and single request processing time without concurrency T is 20+21+20+21=82 ms.
| # of users | Theoretical request processing time |
|---|---|
| 1 | 82+(1-1)*20*2 = 82 ms |
| 2 | 82+(2-1)*20*2=122 ms |
| 3 | 82+(3-1)*20*2=162 ms |
| 4 | 82+(4-1)*20*2=202 ms |
Note a couple of interesting things about JMeter test results.
The timing for the 2 user test is further away from the theoretical value because it waits only for the previous request to finish its synchronous call and its own synchronous calls fit into asynchronous gaps of the other request, so it does not wait as much. More than 2 concurrent users with this request pattern run more synchronous calls and leave no gaps in the Node thread and each concurrent user has to wait for their turn as described.
The above also means that having asynchronous calls that take considerably more time will allow more concurrent users run on the Node thread while those longer asynchronous calls are in progress.
Another interesting observation is that the standard deviation for each user increases as the number of concurrent users grows. This is because some asynchronous calls get in quicker onto the Node thread and asynchronous calls for other requests wait for their share of synchronous calls, as well as those skipped by luckier requests. On the timeline chart that translates into some requests return as if there is no concurrency, while others take much more time than the theoretical result would suggest
Practical thoughts
Different types of Node applications have different practical concurrency requirements.
Command line utility-type applications most of the time execute just one task, so there is no multi-user concurrency and one just needs to find a good balance between synchronous and asynchronous calls and their implementation to handle well parts of that task that can and cannot be parallelized. If the task cannot be parallelized, then there is not much benefit in having asynchronous calls at all - the main thread will just wait for callbacks to fire and the code will be more complex to maintain.
Small web applications that handle a few thousand requests per day will work fine using just about anything Node has to offer. For example, an application that handles 30K requests per day will likely serve about 2/3 of this traffic within an 8 hour window, which yields about 20K/8hr ~ 0.7 req/sec. Under this load, even requests that take 300 ms usually work out without upsetting users too much, even if occasionally some take 2-3 times longer
The biggest problem for small applications is not the concurrency introduced by multiple visitors, but rather request bursts from UI pages. That is, if a UI page needs to make 5 separate API requests to render fully and each one of them is needed to render the page, then asynchronous calls of all outstanding requests will have to wait for synchronous calls of other requests. These 5 requests will be stomping on each other, so the last one will wait for synchronous calls of the 4 requests before it and so on, resulting in more than a second page load times.
Small applications may even get away with serving static content via Node and not having multiple Node processes, as long as something is there to restart a Node process when it stops.
Medium-size web applications processing about a hundred thousand requests per day will require more careful consideration for Node package selection and coding practices. A medium-size application would process about 70K requests in an 8 hour window, which translates into 2.4 req/sec. At this rate 300 ms processing time does not leave much wiggle room for performance glitches.
Knowing how much synchronous code is in dependency packages will go a long way. Writing JavaScript might be good for your own application development, but the less JavaScript is used by dependency packages, the faster the application will run. It also means that JavaScript-heavy dependencies, such as ORM tools, might need a good second look to see if simpler and faster alternatives would work just as well for development.
Good coding practices and code reviews will do wonders for such applications. An asynchronous request thread holding a database lock crashing without releasing the lock will always result in a flurry of angry phone calls at various levels, as will a synchronous call transforming a 10K result set into some other representation format, as will a myriad of other issues that would take ten blog posts to describe. Having good code maintenance hygiene, good monitoring tools and multiple Node instances that can quickly take over failed traffic will often provide a necessary relief to buy Development some time to figure out the problem.
Combining multiple API requests into a single call will often improve performance, but will likely make API more difficult to design and manage, as instead of using well-defined API endpoints one would have to route requests at the payload level, which would contain multiple, possibly unrelated API requests. In addition to this, if such routing is done in JavaScript, then it will be synchronous, really saving only on the network traffic for individual requests.
Running Node in some form of virtualization will help isolating failing instances from good ones. For example, if one of 5 Node processes on one machine with 4 cores misbehaves and starts consuming 100% CPU on the main thread or, worse, will have a couple of asynchronous calls using up more than one core, the other 4 Node instances will be affected adversely as well. The same can be said about consuming memory - JavaScript does not leak memory, but stuffing some results continuously into an array will prove to be just as deadly for all other Node instances on that machine. Using any form of virtualization that isolates Node instances will help a lot running a more stable application.
Applications that anticipate bursts of activity, such as selling tickets to a popular event, should use queuing in front of an application to allow only as many requests in as all Node processes can handle with acceptable response time. This way waiting users can clearly see that they are waiting and see their position in the queue rather than being frustrated by application responses taking forever and seeing inevitable reverse proxy timeout errors, as the application struggles with too many active requests.
Worker Threads
Workers in Node are still experimental, but it is not quite a new concept. Back in late 2000s, when I was trying to figure out how to run code faster in Node, I found a Node spin-off project, called JXCore, that did pretty much the same thing that Node Workers offer now, except that JavaScript then did not have faster and more convenient ways to communicate with workers, so the main Node thread would pass serialized JSON objects into worker threads and receive results the same way.
Node workers run JavaScript in separate v8 Isolates and pass data between the main Node thread and workers in ArrayBuffer instances and messages via message ports. Node workers are not quite like native OS threads in that they need to spin up an entire v8 Isolate to work, which is not cheap, so they work better if they are being reused and run heavier tasks, like reports or email campaigns.
Using workers for request processing is not very practical because they need to synchronize back with the main Node thread and may just hang there while it is running a long synchronous call, they are not as easy to monitor with external tools as separate Node processes and if a Node process crashes, more users will feel the pinch because a Node instance with worker threads will be configured to handle more users.
Having said that, they can certainly improve application performance, if used carefully, but then again, in this case there are other ways to improve application concurrency to consider and Node worker threads may not necessarily be not the best choice.
Just JavaScript
If you need to run JavaScript on the server, but do not have heavy dependency on npm packages, you can embed v8 directly into your code and run multiple JavaScript applications in parallel within your backend.
v8 is beautifully designed to allow very tight integration with C++ backends and it is not particularly difficult to manage a few v8 Isolates and implement a set of application objects visible in JavaScript that can run all sorts of useful JavaScript code that can be maintained in a more flexible way than a typical application written in C++ and other languages, such as reporting, analytics, email campaigns, and so on.
Note that if you want to run your own v8 Isolates withing a Node application, you would need to build the v8 in a static library, so it does not conflict with the v8 shipped with Node and any of its components, such as the ICU libraries
Conclusion
We are living in wonderful times when servers with 16 and 32 cores become more or less affordable to a wider audience. A single Node instance can use just one, maybe a couple of cores, if we count built-in asynchronous I/O handlers. Berkeley researches predict that there will be hundreds, perhaps thousands of cores in not too distant future.
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.pdf
Will we have to run a Node instance per each couple of CPU cores to take advantage of this power? Node is truly remarkable in many aspects and it did revolutionize the Web, but I cannot help but wonder if JavaScript will still be the language of choice when we run our future software on a hundred-core server.