Squashing commits is not a particularly new concept - one could always get a diff between two non-adjacent commits or dates, before multi-file commits came about, and produce a combined patch of changes, similar to how squash commits work, which was useful for submitting patches to another project and other similar uses, when recipients were not interested in development details and wanted just the patch.
In recent years squash commits started gaining popularity, but far too often they are used as a new fashionable way of doing things, rather than for a specific purpose, which yields oversized and poorly structured commits that are harder to review, graft and trace in a bug tracking system.
There are two distinct patterns of how squash commits are commonly applied. One is to collapse commits when a feature branch is ready to be merged into its base branch and another one is to rewrite history via an interactive rebase.
Feature Branches
Before feature branches became the de facto code review mechanism, code reviews were done either by committing changes directly on the intended branch and then following up with subsequent commits to address code review issues or by submitting patches to a separate code review system, which maintained all pending changes in its own database, provided ways to update changes under review from the working directory and integrated with source repositories to enforce code review approvals.
The first approach routinely caused broken CI builds and gave QA headaches because active branches often contained volatile code changes. Despite these shortcomings, this method provided a clear view of the development timeline for all features, which was quite useful when tracking down reasons behind code at a later time.
The second approach required additional software, hardware and maintenance, but worked really well for bug fixes and small-to-medium features because many coding issues were caught before they were committed into the source repository.
Review Board, for example, accepted patches from developers and created code reviews that were neatly organized on the Review Board server, along with a clear indication of all intended target branches, associated issues in the bug tracking system and selected reviewers. Each subsequent patch would combine with previous patches for its review and start a new round of reviews and comments.
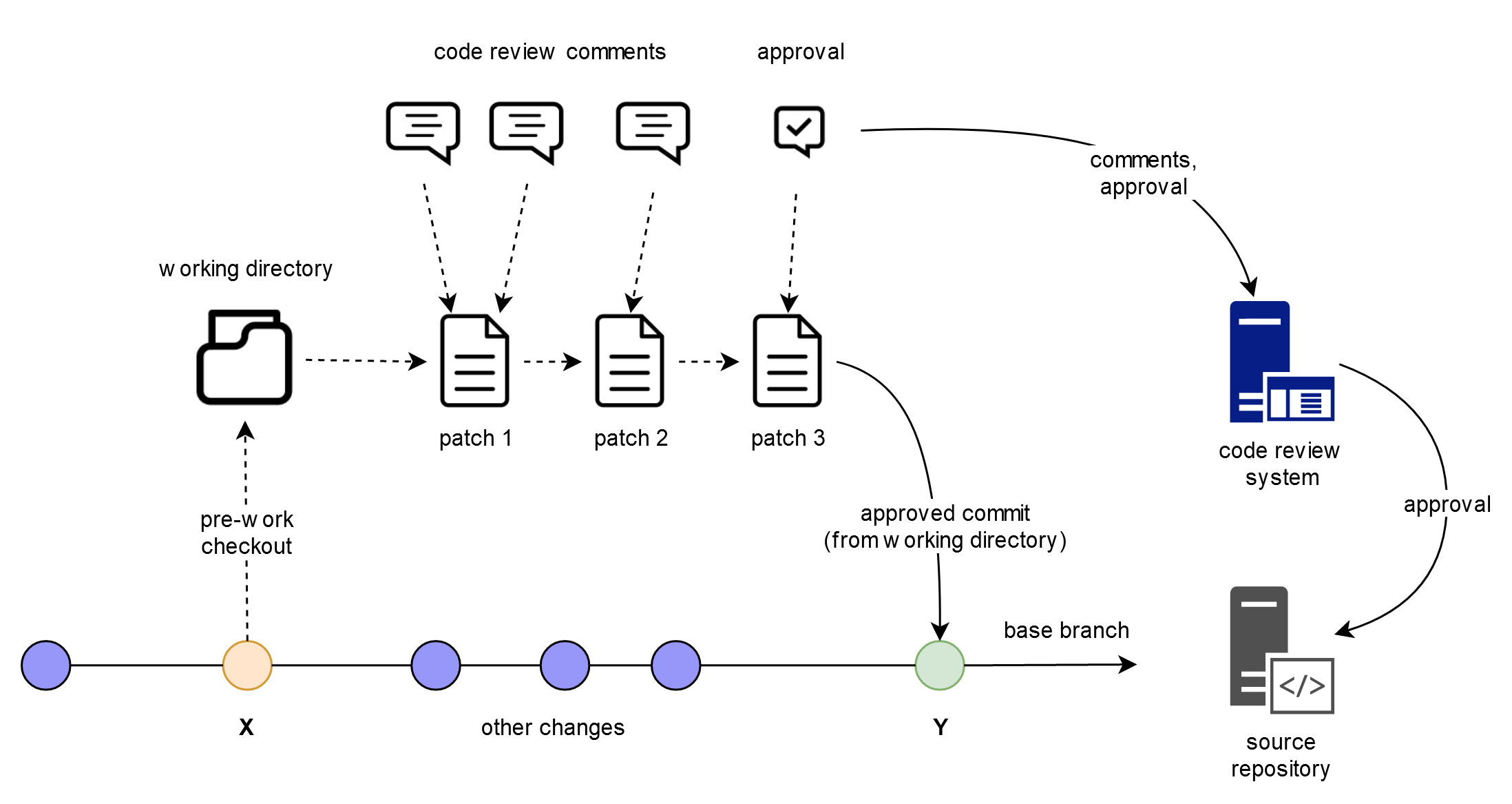
After all reviewers were satisfied with the changes, the review was approved, which allowed the developer to submit the final patch to the source repository for each branch listed in the code review and update the linked issue with the information about the code review.
One of the challenges I found with separate code review systems was that with larger features, the development went through a number of code review iterations and some of those iterations would have been useful as separate commits in the repository, but all changes were rolled into a single patch at the end of the review and one had to jump between the source code repository and the code review system in order to figure out reasons behind some code, which wasn't very productive, compared to just browsing a source file with revision annotations.
Feature branches bridge the gap between these two approaches and make it possible to keep intermediate commits in the repository, conveniently tucked away in feature branches until they are ready to be merged into their base branches.
As a side note about feature branches, they could not be widely adopted until label-style branches were invented, in which a branch label is moved along with new commits, as opposed to embedding a branch identifier into the commit itself. The latter works well for branches intended to remain as branches for eternity, like release branches, but if such branches were used as feature branches, source repositories would contain a branch per issue in a bug tracker and would be hard to manage. Mercurial uses a very nice approach and implements both flavors - it has bookmarks for Git-style branches and it also supports traditional branches, which makes it very easy to track issues in releases - a single commit tells exactly which release branch it is in, without additional queries.
Feature branches provide a good way to separate new development for a specific feature or a bug fix when there is more than one developer on the team, even without any additional reasoning, so no one is breaking CI builds or interfering with QA efforts or automated tests. As an added benefit, all source repository hosting services provide code review functionality based on feature branches and pull requests. The latter is a misnomer, as it is really intended for 3rd-party developers to implement a patch in a cloned repository and ask the original maintainer to pull their changes, which eliminates the need for numerous users with push permissions, but the name stuck and now code reviews are done via pull requests, even within the same source repository.
In the feature branch development workflow, a developer checks out the code at revision X, works on the issue and creates a couple of local commits A and B, at which point they consider changes complete, push the feature branch and create a pull request for others to review these changes. Other developers provide comments and additional changes C and D are introduced in response, the pull request gets approved and is allowed to be merged into the base branch, which would have been the revision Y.
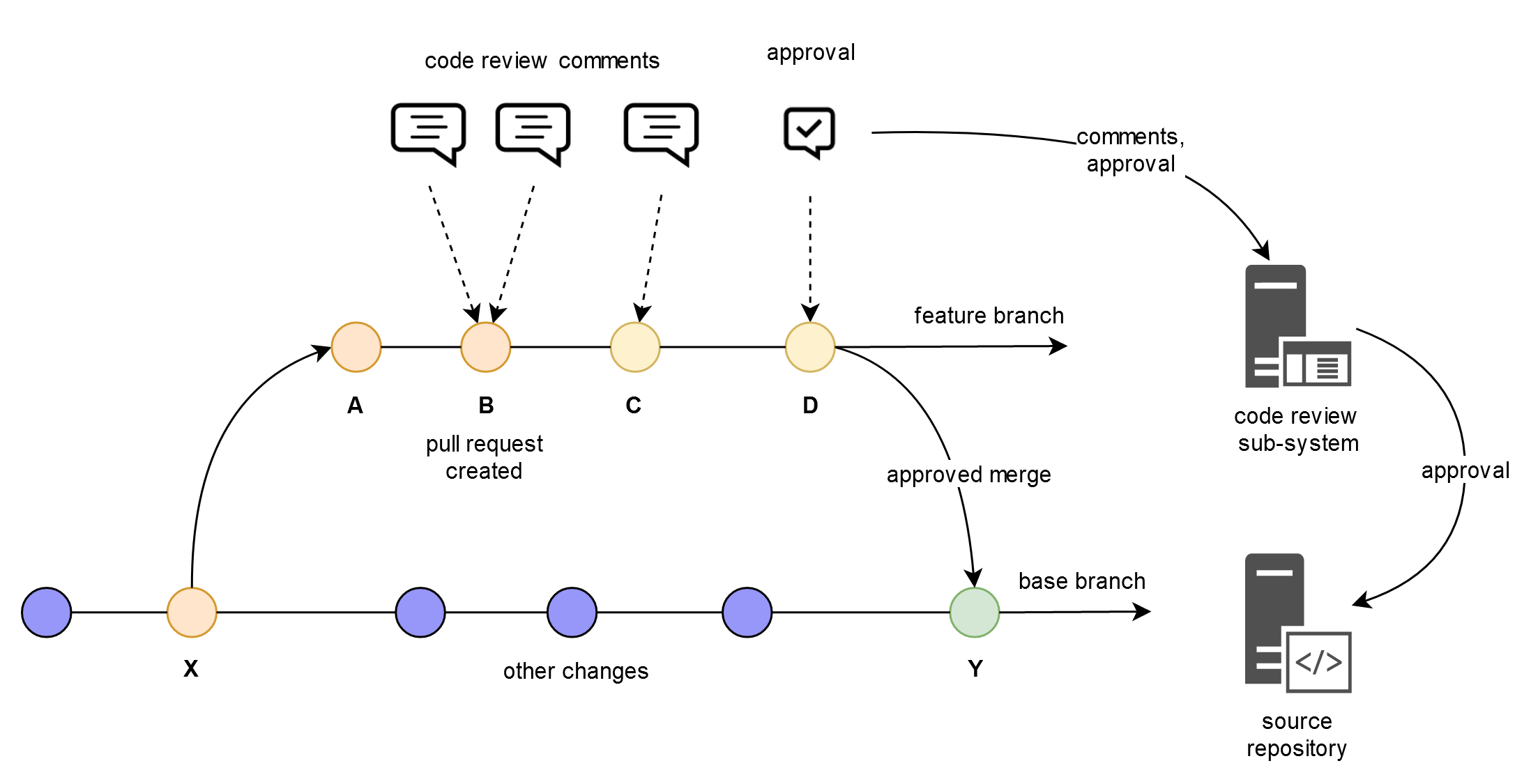
This is where the decision of how to merge a feature branch into the base branch is made and the choice is to a) merge it into the base branch b) rebase feature branch onto the base branch, or c) create a squash commit on the base branch.
Before reviewing each option, let's have a look at the commit quality, which plays important role in the decision of whether original commits should be preserved or not.
Commit Quality
Source repositories serve a specific purpose - to maintain source code as a sequence of distinct changes, which is useful for grafting commits onto other branches for bug fixes, tracing commits via an issue tracking system, identifying what went into specific builds for triaging bugs, annotating/blaming when digging through the history and bisecting changes to find where a bug was introduced, just to name a few.
Many developers, however, confuse feature branches with a backup and commit often and with generic descriptions, such as "Oct 10th", and after the feature branch is pushed for a code review, continue this trend with more generic commit descriptions, such as "Addressed code review comments" or "Fixed bug ABC-123", which are just as meaningless as backup-style commits. There are better ways to backup work in progress and even if a source code repository is used for this, it should not be in the remote feature branch of the primary source repository.
Commit descriptions should reflect what exactly was changed and which issue that change was supposed to address. It is important to note that issue references are not a replacement for change details, but simply provide a way to link changed lines of code in the commit to an issue in the bug tracking system. One must be able to see what exactly was changed in each commit without sieving through bug details, which most of the time will not even provide any reasoning as to why the code was written in a certain way, and for long-running projects the original bug tracking system may not even exist anymore.
Another important point about annotating commits with issue identifiers is that there must be one requirement-level issue referenced in any single commit, which typically will be a user story, and not a task or a feature. Having multiple issues per commit shows poor commit hygiene and makes it harder to associate changed lines of code with issues, produce a meaningful list of issues addressed on a particular branch or graft changes onto other branches, such as applying bug fixes to release branches.
Feature Branch Merge
Feature branch merge creates a merge commit on the base branch and, optionally, deletes the feature branch name, leaving the topological branch in place, so all commit hashes remain the same.

It should also be noted that if there are no commits on the base branch since the first commit on a feature branch was created, Git will fast-forward the merge and will just move the base branch label to the last commit on the feature branch, leaving all feature branch commits intact. The end result is as if the feature branch was rebased, but without creating new commits. You can avoid this behavior with --no-ff option when merging, but since all commit hashes remain the same, all repository integrations will work as expected and there are no undesired side effects when this happens.
For good quality commits on a feature branch, merging it into the base branch is the best option preserving the feature development timeline and providing excellent code annotation and robust issue linking.
If code on a feature branch is committed in self-contained increments and each of them can be built and tested without breaking existing functionality, it allows setting up a CI build against feature branches, so unit tests and integration tests can run throughout the feature development.
Self-contained commits also make it easier for a developer to work with smaller changes and track work for each increment with a separate task, although tasks are not very good for issue linking because one cannot get a single list of requirements addressed on a particular branch without having some kind of an integration with the issue tracking system to figure out requirements (e.g. user stories) from task numbers. Tasks also tend to be added and removed more freely than user stories, which may orphan linked commits.
It is also easier to review code for such commits because each change is thematic on some level, such as a adding a new interface, adding new set of tables or collections, implementing dynamic caching, and so on.
Large features may contain multiple requirement-level issues maintained in the issue tracking system either under a feature or an epic. A merged feature branch will perfectly preserve all different referenced issues in commits.
Merged feature branches work with Git's bisect and being able to build and test code at each commit makes it easier to find the offending commit, compared to a larger commit with a lot of changes.
Finally, if changes in a merged feature branch need to be cherry-picked onto some other Git branch, typically a past release branch, there is a choice of either cherry-picking the entire feature branch as series of commits or as a patch.
Feature Branch Rebase
Feature branch rebase moves all feature commits onto the base branch, so everything related to self-contained commits in the section above works for rebased feature branches.

What is different here is that there is no longer topologically identifiable stretch of commits, so any operations against those commits, such as cherry-picking, will have to use specific revision ranges to include just the rebased revisions.
One unpleasant side effect of creating rebased commits is that each of them will have the same commit description, but a new commit hash, which means that any linked issues will be picked up again by the issue tracking integration, unless some filtering is implemented to skip updates from the feature branch, which will become invalid after the rebase. The same applies to other integrations that rely on commit hashes. This might get tricky.
Another potential problem with rebased commits lies in the fact that such commits may break Git bisect if they were committed on the feature branch without checking that the project builds and all tests run successfully, so one of those commits may fail during bisect iterations, making it more difficult to troubleshoot problems.
One also has to be mindful that the original commit time for rebased commits is preserved as author time and the time when rebase was performed is captured as committer time.
Rebasing a feature branch makes source repository look less tangled. It is, effectively, as if a feature branch never existed and a developer applied a bunch of patches imported from the code review system directly on the base branch. Topologically, neither approach is more restrictive than the other, so it really is more of a preference which one to use, just based on the commit topology.
However, things get more complicated for any integrations with other systems, especially if such integrations don't come with the source repository hosting service, which at least will try to deal with new commit hashes produced after a feature branch was rebased.
For example, a simple issue linking integration, such as adding an issue comment on every commit in a build, will leave past comments with dangling commit links that no longer work. Even more established vendors may not handle it well. On the moment of this writing, Azure DevOps will keep old links in the linked issue, except that the last commit will be duplicated - one with the old commit hash and one with new. Old links will still show changes, but much of the accompanying information will be messed up because the commit no longer exists and Azure DevOps uses some hack to keep it around for historical references.
Feature Branch Squash
A squash merge, true to its name, creates a single commit on the base branch with all changes from the feature branch combined and the commit description edited at the squash time.

Squash commits may be useful for times when feature branch commits are poorly described or contain code in the form that may get in the way of future investigations if preserved in individual commits on the base branch, such as backup-style commits failing builds or tests, which may interfere with running Git bisect on the base branch.
Some meaningless commit messages, such as "addressed code review comments", will not break anything, but will force people to have a look at the code when looking at the revision log because the commit subject says nothing about the change.
Unstructured commits in the feature branch are also harder to review because there is no common logic in each commit and reviewers have to juggle commit selection in a way that produces a meaningful change and when new commits appear, they cannot just review all commits since the last review and instead have to repeat that exercise in finding a new range of commits.
Large features that change a lot of existing code can still be reviewed as individual commits while they are on a feature branch, but after commits are squashed, those descriptions will be lumped together and it will make it harder to understand affected code when doing historical digging because there will be no implied association between combined commit descriptions and groups of changes that used to be in commits.
Merging a feature branch with commits that link to different issues via a squash merge would pile up all different issues in a squash commit description. That would be a bad thing to have any way you look at it because one commit will be linked to multiple issues and there will be no way to logically attribute code changes to issues.
Lastly, issue linking is affected by a squash merge more than it is by a rebase because not only commit hashes change, but also all commit hashes are replaced with a single one, so issue tracking integration would have to be more elaborate in addressing any issue links created on the feature branch when it is squashed.
Squash/Fixup Rebase
Git's interactive rebase provides another squash commit pattern that comes in handy from time to time either to correct mistakes, before they are pushed to any shared remote repository, or to deal with intermediate commits while working on a complex feature that may take many days to design and develop.
For example, if some encryption key or a huge 3rd-party framework were checked in by accident, these commits could be removed with a fix-up operation, which is implemented via a squash commit. Similarly, if a local repository was used as a backup during a lengthy feature development or a few experimental commits were created before the final design was implemented, some of the intermediate commits may be squashed into meaningful self-contained commits before the feature branch is pushed into the shared remote repository.
Consider the topology below. The light red commit X contains something we want to remove, the violet commits are backup-style commits and the light green commits are good commits we want to keep as-is.

We edit out the unwanted bit in the current working directory and add a fix-up commit for X (5d1f8c70). Notice that there no commit message for this commit because it is intended to merge with the earlier commit. You can still add one and it will be maintained until the subsequent rebase, but there is really no point.
git commit -a --fixup 5d1f8c70
This yields the branch below - so far not much different from any other commit, except that the dark green commit at the end will have a commit description fixup! X, where X is the subject of the commit we want to correct, not its hash.

Now we run an interactive rebase with the ancestor of X (5d1f8c70) as the upstream:
git rebase --autosquash --interactive 5d1f8c70~1
, which will bring up an editor, where we replace pick against second and third violet commit with squash, which indicates that they will be squashed into the first violet commit and Git will automatically move for us the fix-up commit next to X based on that fixup! commit subject.
pick 5d1f8c70 X fixup 594750c fixup! X pick 670215c backup commit 1 squash b513207 backup commit 2 squash 4ff694e backup commit 3 pick 18841f0 good commit 1 pick 8bfa3f0 good commit 2
After this another editor pops up to allow us to edit the commit message for squashed commits and we end up with this topology, with the bottom dark gray part gone and shown just for visualization purposes. You can also see the original branch if you enable Git's reflog view in your Git UI tool, if it supports such view.

Backup-style commits after the first one may be accompanied with --squash to automate the rebase process, so each will look like this:
git commit -a -m "backup 2" --squash 63c4a803
, where 63c4a803 is the hash of the first backup commit.
Interactive rebase with fixup and squash might be useful to correct glaring mistakes before they are pushed to a remote repository or for keeping a record of changes during lengthy development, but rewriting history like this is not sustainable as a general strategy for shared repositories because this process is error-prone and is based on how well everyone on the team follows the instructions to reset their copies of the repository.
Rewriting history in team repositories also negates testing that was done against affected commits because one would have to build all packages from those commits again and confirm that everything works exactly the same way as before. New commits also will have new commit hashes, which means all existing commit references in the issue tracking system and other integrations, such as build artifact management, package management, etc., will be broken and some will be harder to fix than others.
In a word, if you checked in a key to your AWS account or a credit card number or a 500MB framework and pushed the changes, it may be worth going through the trouble of fixing-up the bad commit, but otherwise don't let that crooked branch or poorly structured commit bother you too much after it ends up in a shared remote repository and it will eventually fade into oblivion, as long as you do not keep piling up new ones.
Conclusion
Squash commit is just one tool in a source control toolbox and it definitely has its uses when one needs to throw away unwanted commits. Applying it universally for all incoming changes will lose some of specifics about the feature development process and may require source repository integrations configured to ignore feature branches, so only squashed commits trigger notifications and generate various commit-related links.
If a simpler commit topology with larger and more finalized changes is your goal, then squash commits of feature branches will work for you. In fact, you might be even better off using a separate code review system, which will produce the same topology, but those systems will do a much better job at maintaining intermediate patches with all details, compared to most repository hosting services. Otherwise, focusing on producing self-contained commits and sticking with merge commits will go a long way with code reviews, issue tracking, patching, testing, historical digging and a bunch of other development activities.
Diagrams in this post are created with app.diagrams.net.