Traditional packaged applications rely on the application version to communicate to application users the set of features included in a package and the impact of upgrading from one version to another for applications with carefully maintained versions.
Website applications, on the other hand, are often upgraded by the website operator in their own environments and website users usually have no idea what version of the application is running behind the website UI, even if there is one.
Website applications are centered around user-visible features, which are being continuously developed and deployed to production environments, so grouping features into version levels for such deployments makes very little sense.
Different deployment, different branching
Development and deployment patterns of a website application require a branching strategy that allows one to select a set of features for the next release without having to revert prior commits, be able to queue features that didn't make it to the last release for releases that are further away and to release hot fixes without disrupting ongoing feature development.
A branching strategy that focuses on features, as opposed to alternatives mentioned further in this post, accomplishes exactly that and makes it very straightforward to decide which features should be released next and which should be kept on ice until one of the subsequent releases.
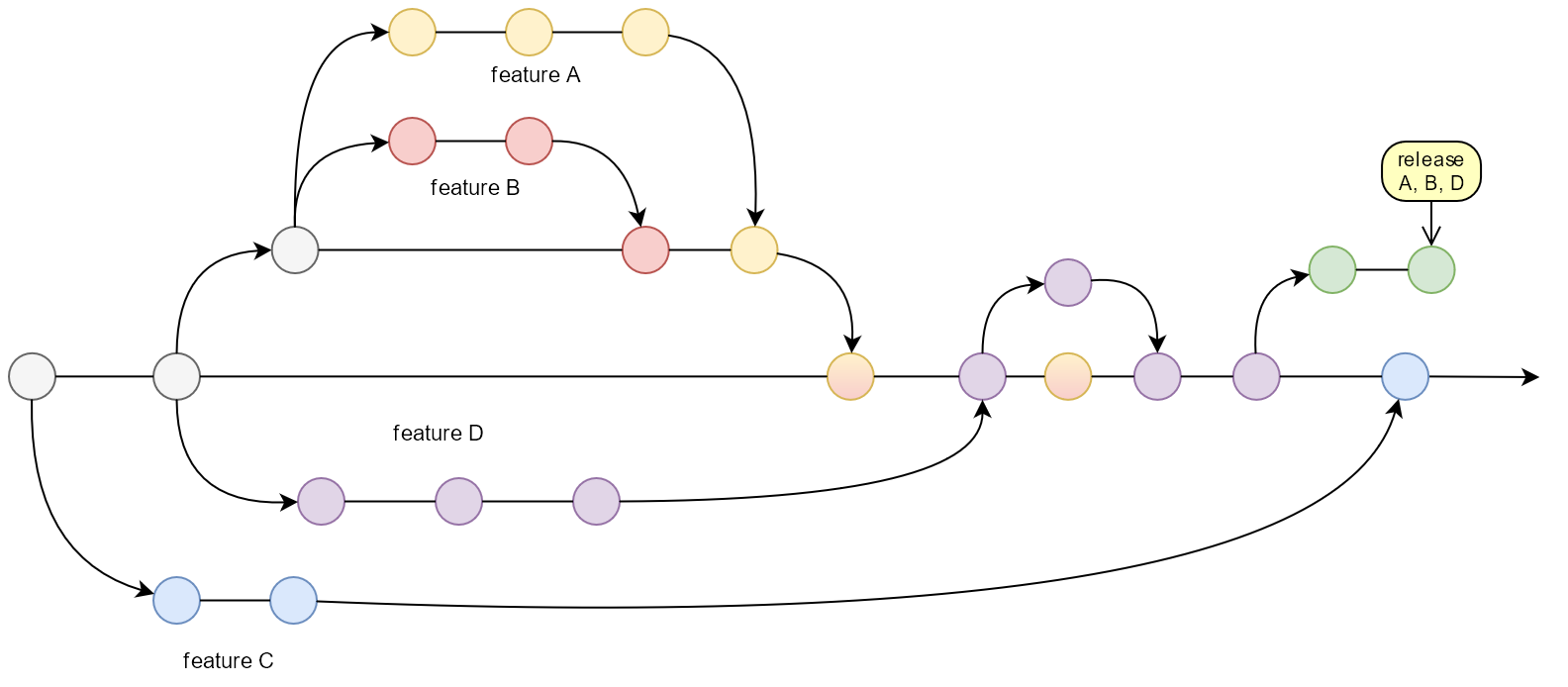
Consider features A, B, C and D being planned for the next release. Features A and B are a part of a larger set of requirements and their development is being tracked with user stories within an epic and features C and D are smaller features and are being tracked on their own.
Each feature is being developed on its own branch, but features A and B only work together and must be tested and released together, so they are developed on an epic branch. This topology translates into three branch heads that at some point will be ready for the next release, as shown on the diagram below.

Let's say before the next planned release QA has time to test 3 out of 4 features and Product Owner chooses features A, B and D. The epic branch with features A and B, as well as the feature branch D, are all merged into main and QA starts their testing. The branch for feature C remains unmerged for the time being.

Each merged feature branch on this diagram has gone through at least one round of automated testing when it was merged into main, perhaps more, depending on the CI pipeline setup for feature branches, and the QA team picks up whatever testing could not be automated.
Any bugs found via automated testing or by QA after feature branch merges are fixed in main using transient work branches, which topologically are no different from feature branches, but may or may not remain as branches, depending on whether fast-forwarding or commit squashing was used after code reviews and automated tests on those work branches are completed. Bug fixes for all features can intermix on main because at this point it is considered as a branch with features A, B and D combined, leading to the next release, which also includes all of the bug fixes introduced after feature merges.
Once all forms of testing are completed, in the simplest case the final commit is tagged as a release and feature C may be considered for the next release, in which case it is merged into master for the next release, or postponed again, maybe with some retrospective discussion as to why it was planned to be worked on a bit too early.
If the release requires some preparatory work, such as updating release notes, documentation or even implementing a fix for a bug that was discovered late in the game, a release branch may be created instead of a release tag, which will contain those additional commits and a release tag, after which it will be merged back into main.
This release tag, whether on main or on a release branch, is critical in allowing hot fixes released between feature releases for any issues found in production that cannot wait until the next feature release. Such issues are fixed on the release branch, tested, tagged and deployed to production as hot fixes.
After a hotfix is released, the release branch may be merged back into main, but in most cases cherry-picking hotfix commits would keep the repository topology less convoluted, especially if more than one hotfix is needed, which would require multiple merges. Whichever way hotfix commits make it into main, they would need to be tested there to make sure they work with other changes.

One interesting observation that is not immediately visible in these diagrams is that while in traditional applications the span between versioned releases may be measured in months, which is required to implement and test all features included in a released version, website application features may be released every sprint, as features are continuously implemented and verified.
Consequently, each subsequent release obsoletes the previous release branch because there is only one website, which is always updated from the latest release branch. Large regional deployments may extend the time between releases and introduce more hotfixes for regions running the previous release, but eventually all regions will catch up and once this happens, no more hotfixes will ever be introduced on the previous release branch.
CI, QA, Stage, Release
Traditional applications are built, tested and released as versioned packages and those packages may be preserved for extended periods of time to support customers choosing to run specific application versions without upgrading to newer releases.
Website applications only have one active application version, which is deployed in production and, aside from inter-application package dependencies for internal libraries and subsystems, there is no reason to keep deployment packages around longer than one release cycle. Website application upgrades are often irreversible and even if something goes wrong after the deployment is completed, most of the time deploying old artifacts is not an option anyway.
It is worth noting that internal libraries and subsystems used by website applications may still need to be versioned explicitly or implicitly (e.g. as sub-repositories) in case they are reused in multiple website applications. For example, a payment gateway micro service may be used by two web site applications within the same company and each may be relying on a different micro service API version. Similarly, an internal data layer library may be used in a similar fashion by multiple website applications.
Many modern DevOps platforms offer multipurpose pipelines that can be used for continuous builds and releases, such as GitHub Actions, AWS CodePipeline, BitBucket Pipelines, Azure DevOps Pipelines, JFrog Pipelines, and some others. Some, like Azure DevOps, offer a more specialized release pipeline functionality that consumes build artifacts from CI pipelines and offers good traceability of release activities and integration with the issue tracker.
Aside from some implementation details, all release pipelines work similarly in that they deploy CI pipeline artifacts from a release branch or a tag onto a set of independent environments organized as a sequence of stages, each deploying artifacts in its environment only if the previous stage was deployed and verified successfully. A typical set of environments would include QA, staging and production, each configured with all resources needed to deploy, test and run the application in the capacity appropriate for that environment.
QA environments need a special mention in that QA needs an environment to test features before a release branch or a tag is created, which means a dedicated release pipeline cannot be configured with a release branch trigger to deploy to a QA environment early in the process. This may be addressed by incorporating QA deployments into a CI build pipeline, leaving release pipeline to deploy from a release branch without any additional logic.
For example, Azure DevOps allows deployment stages in CI build pipelines, which works out well for early QA deployments. Once a release branch is created, a QA stage in the release pipeline would be used for additional release testing and that environment would be physically different from the one used by the CI pipeline. However, QA environments used in a CI pipeline need to be carefully managed to avoid overwriting active environments as CI pipelines keep building.
Long Live the Version
Added on 2021-05-15
Some teams choose to continue using version patterns that resemble semantic versioning for website applications, but these versions don't have much "semantic" in them and are either dictated by the available CI/CD tools or just used as a convenience for naming build artifacts.
For example, Node provides no way of installing top-level applications as packages (global vs. local top-level app installations may be a topic of a future post), so versions of top-level applications are never evaluated as semantic versions because they are installed either via repository cloning or by unpacking artifact files produced by CI pipelines. However, top-level applications still have package.json with an application version string, so people come up with their own version formatting rules for those versions.
Some of those version formats are better than others, but it is important to note that none of them reflects what Semantic Version is supposed to indicate, which is the level of application compatibility between releases labeled with semantic versions.
In general, there is nothing wrong with using semantic-looking versions for web applications, as long as people understand these versions just provide a convenient way of identifying artifact packages and components of these versions do not carry the meaning intended by Semantic Versioning.
I find the most useful versioning scheme for website applications is where the patch level is used for hot fixes and the minor level is used for releases, reserving the major level for the time when the minor level reaches too many digits or when some project milestone was reached. Build numbers in this case work the same way as with other application types and indicate build maturity towards a specific upcoming release.
For example, a CI pipeline may produce artifacts with versions 0.17.2+025, 0.17.2+026 and 0.17.2+027, which means that there are three builds towards release 0.17, hot fix 2, and the most stable build of all three is the build with metadata 027. The fact that there is a zero in the version does not mean that it is an initial development release, like a true semantic version would suggest, but rather that there were 17 deployments to the production environment for this website application.
Other similar versioning schemes may use different sequences, such as date components. For example, 2021.17.1+005 would indicate the 5th build of the 1st hot fix for the 17th deployment in 2021. This scheme keeps the minor level within two digits for most build configurations and provides a hint on when a particular version was released without going to the issue tracker.
One of the least logical versioning schemes is where the patch level is used as a build number and minor/major levels are used for hotfixes/releases. This versioning scheme allows publishing build artifacts to package repositories that are intended for production packages and won't accept packages that differ only in build metadata, as opposed to publishing to specialized package repositories intended for build pipelines, such as Artifactory. Surprisingly, some DevOps services designed specifically for build environments also promote this practice, such as Azure Artifact Feeds, which won't allow build numbers when publishing npm packages and, effectively, force people to use the patch level as a build number.
In and of itself, using patch level as build numbers doesn't break any rules, since versions for website applications are not semantic versions, but this approach has other implications. For example, only one build number may be considered mature enough for the next stage, while any patch level may be selected and installed via npm without restrictions or that the build process must modify the source in order to update the version after each build or that there may be different versions of the package with no functional differences. This approach may also present challenges for teams that maintain both types of packages - regular dependency packages and top-level applications, because without an explicit build number there will be no way to tell them apart looking just at the version alone.
This looks like Gitflow...
Added on 2021-05-24
Gitflow defines master as a production-ready branch that may be automatically deployed to production as it receives commits from release and hotfix branches, where all changes are thoroughly tested before being merged into master.
In any branching topology, after most of the feature work is done, every commit leading towards a release tag is intended to make the source more robust for the upcoming release, which is achieved by repeatedly fixing issues, building artifacts, deploying artifacts and testing the deployed product, in this order, as things may go wrong in each of these stages.
It is that final set of artifacts, which is identified by a build number and passed all the tests, that is considered a release, not the release tag in the source code repository. One cannot just check out the source and deploy it in production, but rather needs a build and a release pipeline to ensure build quality before it goes to production.
Having a dedicated branch that, effectively, contains source snapshots at commit points in release and hotfix branches, which supposedly were used to build and test artifacts on their own anyway, does not add a lot of value and creates a rather convoluted topology with diamond-shaped paths between release tags in release branches and master, where one of the edges on master may not even contain any changes, if there were no hotfixes.
Conclusion
Feature-focused branching strategy makes it very straightforward to identify features included in any particular release. Each branch, effectively, represents either an individual feature, or features grouped by some epic theme, or all features lined up for the next release. Some teams, however, add more levels of branching that are not feature-related, which are aimed to improve build quality, but often end up causing more problems than solving anything.
For example, some teams create a branch per development team and each team periodically merges their branch into main, where changes are tested and prepared for a release. Sometimes a QA branch is wedged into this setup before merging into main. The intent behind this approach is to make it apparent which team breaks anything, but instead it creates an endless barrage of merge conflicts and bad merges at the end of each cycle, plus logical feature streams are lost in the topological web of organizational branch merges.
There is a good chance that a branching strategy that is not structured around features and releases, such as team branches, QA branches, deploy branches, sprint branches, and so on, may be used as a substitute for missing release management tools or development practices.
Today's CI/CD pipelines, package repositories and artifact management services offer such a great spectrum of tools and techniques that there is really no need to overload source code repositories with purposes other than keeping code changes well-organized and clean.
Diagrams in this post are created with app.diagrams.net.